We’ve filed a lawsuit challenging Stable Diffusion, a 21st-century collage tool that violates the rights of artists.
|
AI art tools do not in any way, shape or form "collage together images". No images are stored in the checkpoints in any way, shape or form,[1] and indeed - as documented below - the notion that they just store all their training data is a literal impossibility. Rather, AI art tools work akin to seeing shapes in clouds - starting with random latent noise and trying to make it "make more sense", pushing and nudging it one step at a time,[2] based on the relationships it has learned about what is statistically "normal" in images.[3] |
|
January 13, 2023 Hello. This is Matthew Butterick. I’m a writer, designer, programmer, and lawyer. In November 2022, I teamed up with the amazingly excellent class-action litigators Joseph Saveri, Cadio Zirpoli, and Travis Manfredi at the Joseph Saveri Law Firm to file a lawsuit against GitHub Copilot for its “unprecedented open-source software piracy”. (That lawsuit is still in progress.) |
Regardless of the outcome of the lawsuit against GitHub Copilot, it should be pointed out that it is a fundamentally different thing. GitHub CoPilot is trained on "billions of lines of code"[4] to create checkpoints that are presumably a couple gigabytes of weights and biases. Given that a line of code consists of only a couple tokens on average, the size of the weights is likely similar to the number of tokens to represent; in theory, with overtraining (overfitting) it should readily be able to precisely produce specific code (albeit it, that would not at all be a desirable goal for developers, and much work goes into preventing it.[5][6][7][8][9]) By contrast, AI art tools are trained on billions[10] of images. Each is not a couple tokens, but rather millions of pixels, each pixel being several bytes each. It should be obvious to anyone that you cannot reversibly compress a many-megapixel image down into one byte of information. 8 bits, 256 possible combinations of bits. And indeed, the more training images you add - which generally improves generation quality - the more absurd the notion of storing it all becomes: a fraction of a byte per image, 1 bit per image, a small fraction of a bit... at what point does one accept that reproducing specific images is impossible? If one built a training dataset out of 100 quadrillion images, will one argue that any of those 100 quadrillion images can be reproduced? What about 100 sextillion? Literally infinite? |
|
Since then, we’ve heard from people all over the world—especially writers, artists, programmers, and other creators—who are concerned about AI systems being trained on vast amounts of copyrighted work with no consent, no credit, and no compensation. Today, we’re taking another step toward making AI fair & ethical for everyone. On behalf of three wonderful artist plaintiffs—Sarah Andersen, Kelly McKernan, and Karla Ortiz—we’ve filed a class-action lawsuit against Stability AI, DeviantArt, and Midjourney for their use of Stable Diffusion, a 21st-century collage tool that remixes the copyrighted works of millions of artists whose work was used as training data. Joining as co-counsel are the terrific litigators Brian Clark and Laura Matson of Lockridge Grindal Nauen P.L.L.P. Today’s filings: |
While one can certainly have sympathy for artists who are faced with change in their industry - as has happened many times in the past, to great resistance, such as with the advent of photography,[11] and later, of digital tools like Photoshop[12][13] - the simple facts are, the rights of creators are not unlimited. That's literally what fair use is.[13] In his very critique of AI art "misappropriating" images, the attorney for the plaintiffs himself takes the images of various researchers straight from their papers, "with no consent" and with "no compensation". And that's fine, because, again, there are limits to the rights of creators, and the world is better for the existence of fair use. Indeed, while said attorney took other people's images in their entirety, AI image generators make use of on the order of a byte or so per image. An entire artist's portfolio may be represented in a tweet or two. A Wikipedia page on an artist stores far more. Google thumbnails store vastly more, by orders of magnitude. If using a byte or so from a work, to empower countless millions of people to create works not even resembling any input, cannot be considered fair use, then the entire notion of fair use has no meaning. Again - like many times before - artists are faced with change in their industry brought on by advancements in technology, and while many embrace it, others fear and resist it, and one can have sympathy for those people. But sympathy does not give them the right to throw fair use in the garbage. I can have sympathy for an artist whose dying wish was that nobody parody their works, but that doesn't give them the actual right to impose such restrictions. The authors of the papers whose images the plaintiff's attorney used without permission may not like him doing so, but that doesn't give them the right to stop him if it's done for reasons in the public interest. |
|
As a lawyer who is also a longtime member of the visual-arts community, it’s an honor to stand up on behalf of fellow artists and continue this vital conversation about how AI will coexist with human culture and creativity. |
It should go without saying, but suing someone is not a way to "continue a conversation".[14] It's an attempt to stifle an emerging technology that helps enable millions of people to bring their visions to life, via false accusations about how it works and accusing its users - many of whom were already professional artists - of being criminals. |
|
The image-generator companies have made their views clear. |
Note here how the argument is carefully played off as artists vs. AI tool users, without ever feeling the need to actually defend the point. In reality, many of the people using AI art tools were already professional artists.[15] The case takes the anti-progress side of an "artists who fear change" vs. the "artists who embrace change" debate. |
A 21st-century collage tool
“The Concert” by Johannes Vermeer, stolen from the Gardner Museum Stable Diffusion is an artificial intelligence (AI) software product, released in August 2022 by a company called Stability AI. Stable Diffusion contains unauthorized copies of millions—and possibly billions—of copyrighted images. These copies were made without the knowledge or consent of the artists. |
This is an unabashedly false statement, casually dropped into the argument as if it's an incontrovertible fact. AI art tools - including Stable Diffusion - contain NO copies of images.[1] Neural network weights and biases capture, to put it simply, the statistical relationships between elements[3] - for images, things like shape, colour, position, etc - and in effect function as the reverse of image recognition: making something that's not recognizable become more recognizable.[16] When faced with a latent comprised of random noise associated with the text of "cat", for example, the diffusion model does not "collage in" images (which it does not have), but rather, has learned data distributions. For the word "cat", there might be associations along the lines of, "earlike-shapes this far apart, eyelike shapes positioned here by comparison, a noselike shape proportionally here", so for these parts of the noise that are already a little 'catlike', we'll push them closer to an ideal catlike shape" - or to be less abstract, calculating and diffusing along a gradient.[3] This process continues again and again, at all scales from small to large, until the maximum step count has been reached. Not only are they not in any way shape or form pasting in image data and blending together different images, but any individual image's contribution to understanding what is "catlike" in this context is meaninglessly small. With tens of millions of images of cats, your image of a cat's contribution to the statistical understanding of what is "catlike" is essentially irrelevant. There are exceptions (see overtraining / overfitting later), but again, there are NO images stored in AI art tool checkpoints,[1] and they do NOT collage images (which they don't have). It should be in particular pointed out that, while AI art tools are essentially applied image recognition,[16] there was essentially zero movement against image recognition tools - no accusations that they were "storing images" and "violating copyrights". These accusations only cropped up when a certain segment of artists realized that these tools could actually be used to compete in the art field. |
|
Even assuming nominal damages of $1 per image, the value of this misappropriation would be roughly $5 billion. (For comparison, the largest art heist ever was the 1990 theft of 13 artworks from the Isabella Stewart Gardner Museum, with a current estimated value of $500 million.) |
It would be convenient in law if we could just make up assumed violations, but in reality, we cannot. Copyright is based around works.[18] One must demonstrate that a specific work violates another specific work or works' copyright; it must be representative of said work or works in a non-materially-transformative way and not otherwise fall under fair use. Handwaving is not a substitute for demonstration. The attorney in this case has three clients making accusations. A logical retort would be, show us then. Show us their works, and show us the works that infringe on their works in a non-materially-transformative, non-fair-use manner. Not by someone pasting one of their works into img2img and then ordering StableDiffusion to make minimal changes to it. Not by some custom checkpoint that some random person deliberately overtrained to one or more of their images. Not by generating a million images until you can finally, by random chance, find something that looks like one. Show us actual, realistic infringement of specific works against works of the plaintiffs. He does not because he cannot. |
|
Stable Diffusion belongs to a category of AI systems called generative AI. These systems are trained on a certain kind of creative work—for instance text, software code, or images—and then remix these works to derive or generate more works of the same kind. Having copied the five billion images—without the consent of the original artists—Stable Diffusion relies on a mathematical process called diffusion to store compressed copies of these training images, which in turn are recombined to derive other images. It is, in short, a 21st-century collage tool. These resulting images may or may not outwardly resemble the training images. Nevertheless, they are derived from copies of the training images, and compete with them in the marketplace. |
The very reason why a tweet or two's worth of information about an artist's entire portfolio can be enough to represent their style - but not works - is the simple fact that their style and motifs already exist in the weightings. The tokens associated with their name simply invoke a mix of preexisting associations with styles and motifs. Maybe Artist X's name is associated with long, curvy brush strokes, a muted colour palette, dragons, and fire. Well, those things already exist in the latent space; they don't have to be redefined specifically for Artist X. As an example, using the following set of token embeddings, one can consistently generate photos of Buddha statues simply by an interpolation between the preexisting tokens: cree, pasadena, ish, informal, preview, lindo, kids, potential, statue, calcutta, phenomenal, sigma, chero, heh, âľĵ, kier, bourdain, anjali, ori, and displa.[19] What do those words have to do with Buddha statues? Nothing. But the latent space at a particular superposition between all of them corresponds to things that look like photos of Buddha statues. You don't have to start from scratch in defining a given set of styles or motifs. (More on Somepalli et al (2022) in a bit) |
|
At minimum, Stable Diffusion’s ability to flood the market with an essentially unlimited number of infringing images will inflict permanent damage on the market for art and artists. |
Here we get to the crux of the fears: anti-AI artists being replaced by artists who use AI tools in their workflows. Just like the fear was of manual artists being replaced by digital artists when tools like Photoshop emerged,[12][13] and the fear of painters being replaced by photographers when the camera was developed.[11] But the camera was not the end of painting, and rather, ushered in a boon of painters diversifying from realism to a dizzying array of new styles. Photoshop, too, spawned a whole new wave of artists making art with digital tools, which most of the world's greatest modern artists utilize. And AI, too - incorporated into artists' workflows - will have the same impact. People still, however, continue to buy realist paintings. People still continue to buy non-digital art. And people will continue to buy manual art that excludes all AI tools, from text-to-image, image-to-image, and even many AI tools that artists currently use (such as AI upscalers), from their workflows. This, however, is not good enough for the plaintiffs, who seek to roll back the clock. But the simple fact is, copyright is not a non-compete clause.[20] If a work is transformative - let alone not even remotely the same - then it's not a violation of copyright ("The more transformative the new work, the less will be the significance of other factors, like commercialism, that may weigh against a finding of fair use" - Campbell v. Acuff-Rose Music, Inc., 510 U.S. 569 [21]), and the plaintiff simply has no ground on which to stand to file a copyright infringement case. The plaintiffs must demonstrate actual insufficiently-transformative violations of specific works. Not styles (which are not copyrightable,[22][23] and which artists in general extensively copy and reuse) - works. It doesn't matter if a fantasy author has read Tolkien and writes Tolkien-like prose in a land with elves, dwarves and wizards; if it's not a non-transformative ripoff of a specific Tolkien work, then Tolkien's copyrights are irrelevant to it. |
|
Even Stability AI CEO Emad Mostaque has forecast that “[f]uture [AI] models will be fully licensed”. But Stable Diffusion is not. It is a parasite that, if allowed to proliferate, will make artists extinct. |
It's curious that a thread, headed off by news that Stability AI is going out of its way to try to make anti-AI artists happy by introducing an opt-out feature, is specifically cited against Emad. But the simple fact is - and to be blunt - to any artist who thinks that the dataset will suffer greatly if they're not included, you're not "all that". You can be described in a couple tweets worth of data. Your contribution to the total understanding of styles and motifs is vanishingly small. Stability AI can afford to lose anyone and everyone who's unhappy with being in the dataset. The main challenge has been that this is a surprisingly difficult task. The simple fact is that images get reposted across the internet and are changed via resizing, header modification, cropping, rotation, JPEG noise, added layers such as text, deliberate manipulation, and so forth. Identifying what was the original work and what are non-transformative variants thereof is not a trivial task. But it's a task that it's a good gesture that they're spending their resources to embark on. Ironic, then, that this is being used as an attack vector against them. To put it quite simply: saying "since you're annoyed with X, I'm going to stop doing X" is not the same thing as saying "X is illegal" - however much one may want to twist someone's words. |
The problem with diffusionThe diffusion technique was invented in 2015 by AI researchers at Stanford University. The diagram below, taken from the Stanford team’s research, illustrates the two phases of the diffusion process using a spiral as the example training image. 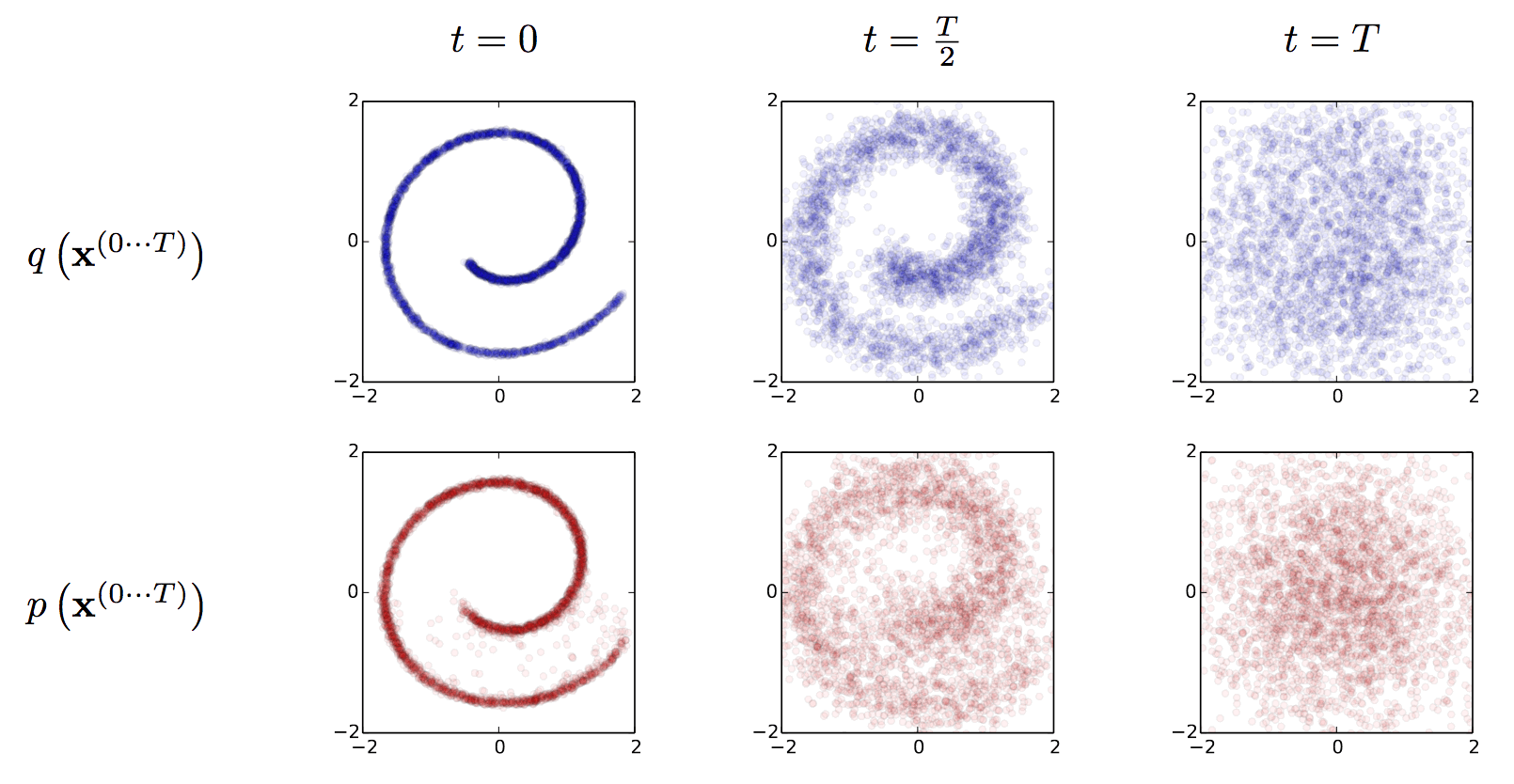
The first phase in diffusion is to take an image and progressively add more visual noise to it in a series of steps. (This process is depicted in the top row of the diagram.) At each step, the AI records how the addition of noise changes the image. By the last step, the image has been “diffused” into essentially random noise. The second phase is like the first, but in reverse. (This process is depicted in the bottom row of the diagram, which reads right to left.) Having recorded the steps that turn a certain image into noise, the AI can run those steps backwards. Starting with some random noise, the AI applies the steps in reverse. By removing noise (or “denoising”) the data, the AI will emit a copy of the original image. In the diagram, the reconstructed spiral (in red) has some fuzzy parts in the lower half that the original spiral (in blue) does not. Though the red spiral is plainly a copy of the blue spiral, in computer terms it would be called a lossy copy, meaning some details are lost in translation. This is true of numerous digital data formats, including MP3 and JPEG, that also make highly compressed copies of digital data by omitting small details. |
Here is the first of a gross misrepresentations of papers, to the degree that it's difficult to tell whether the author even read the papers at all, read but didn't understand them, or is deliberately misrepresenting them. First, there is no "record[ing] the steps", and then "run[ning] those steps backwards". None. He literally just makes that up and asserts it as fact as though it's in the paper. It is not, is not a part of how diffusion networks work, does not exist in the weightings, and does not even make sense (that wouldn't reverse arbitrary noise, and would take up dozens of times more space than the image itself). Second, the specific example he chose is the toy problem[24] of a single "Swiss Roll distribution" of 2D points - effectively training a network with numerous layers on a single training input. Literally the only thing it has to capture is that one distribution, and it has a huge number of weights from which to capture that specific distribution's statistical relationships. Train it for long enough, and convergence of points to somewhere on that one specific distribution (not necessarily where they began) is guaranteed. 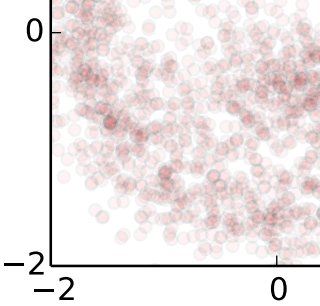
These are points on a grid, not pixels in an image. And they do not return to their starting points. But what happens when you train on many actual images? Well, the paper did that. They trained it on the CIFAR-10 dataset of 60,000 64x64 images representing 10 types of objects.[25] And this is the result of what we would consider txt2img without any text guidance (fig 2. d.): 
I think it goes without saying that you're not going to find any of these... "things"... in the image dataset. If the goal were to show you that, by deliberate effort, and with thousands of layers of weights and biases dedicated to representing just a single distribution, and sufficient overtraining, you can get 2d points to drift to somewhere on said distribution, then job well done. But that isn't even tangentially related to the accusations being made, relative to a system that has only a byte per image of weights and biases. |
|
In short, diffusion is a way for an AI program to figure out how to reconstruct a copy of the training data through denoising. Because this is so, in copyright terms it’s no different from an MP3 or JPEG—a way of storing a compressed copy of certain digital data. |
To paraphrase: "In short, because it's possible for someone to deliberately encode a single I think it goes without saying how absurd of an argument this is. How far do the plaintiffs want to take this digital homeopathy? Billions of images into a 4GB checkpoint? Apparently in the view of the plaintiffs, they can all be stored and reproduced. Into a 1GB checkpoint? Stored. A 1MB checkpoint? Stored. A 1kB checkpoint? Stored. A 1-byte checkpoint? Stored. A 0-byte checkpoint? Might as well declare that stored as well. There appears to be no level of "dilution" to which the plaintiffs would not accept that there are no "stored images". |
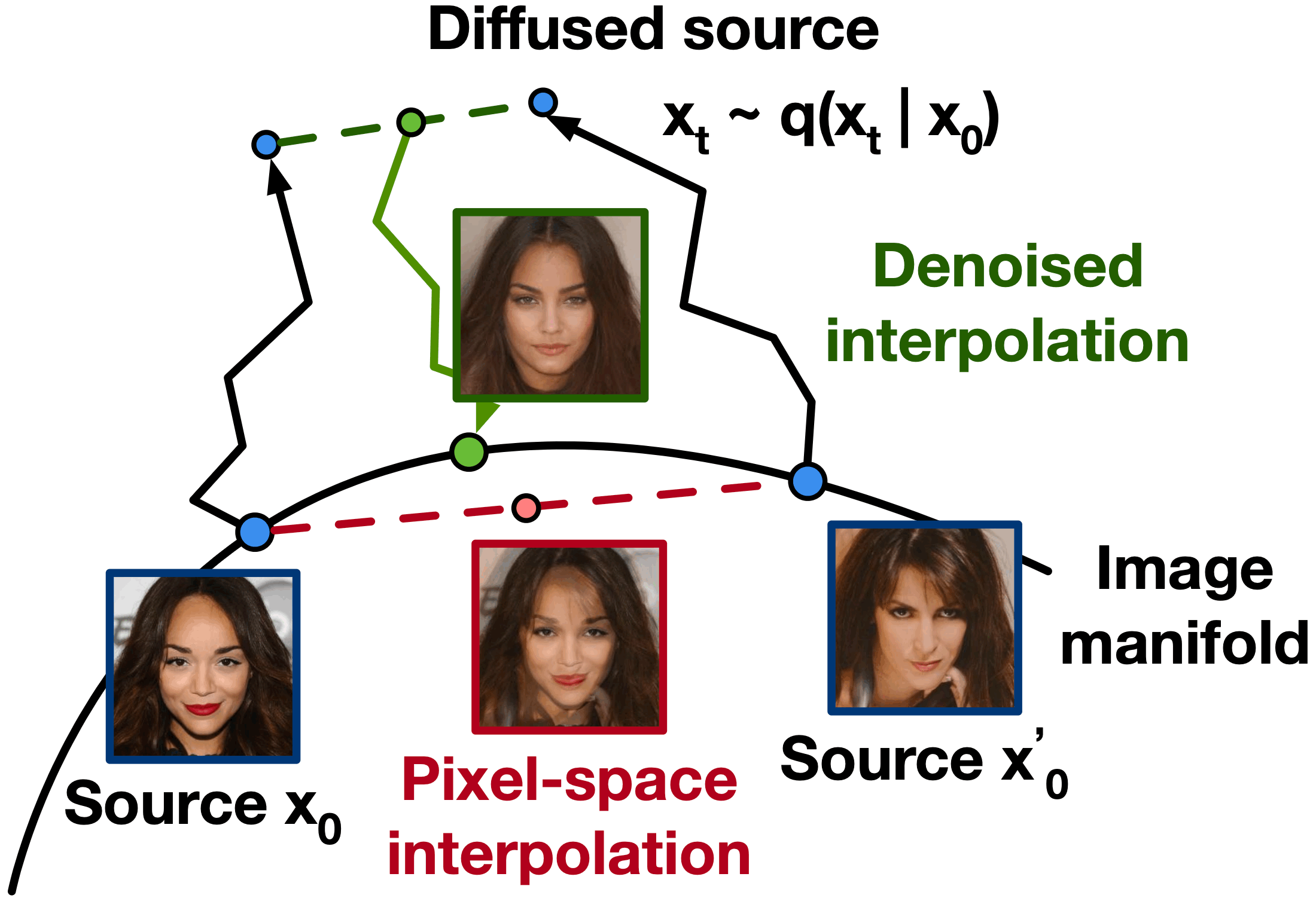
Interpolating with latent imagesIn 2020, the diffusion technique was improved by researchers at UC Berkeley in two ways:
The diagram below, taken from the Berkeley team’s research, shows how this process works.
The image in the red frame has been interpolated from the two “Source” images pixel by pixel. It looks like two translucent face images stacked on top of each other, not a single convincing face.
The image in the green frame has been generated differently. In that case, the two source images have been compressed into latent images. Once these latent images have been interpolated, this newly interpolated latent image has been reconstructed into pixels using the denoising process. Compared to the pixel-by-pixel interpolation, the advantage is apparent: the interpolation based on latent images looks like a single convincing human face, not an overlay of two faces. Despite the difference in results, in copyright terms, these two modes of interpolation are equivalent: they both generate derivative works by interpolating two source images. |
This entire section serves only to illustrate one thing, and that is that the author has no conception at all of how diffusion models work. It appears, from this, that he believes that they work the following way:
1. Latent images are generated and stored in some sort of database. 2. When someone runs txt2img, it looks up similar latent images and mashes them together to create a "collage". 3. It then converts that collage back into image space. I think by this point you should understand that this isn't even remotely, in the slightest how diffusion models work, and understand that storing billions of latents - at 64x64x16[26] = ~66k each - would take a good fraction of a petabyte of space per checkpoint ("hey, everyone running StableDiffusion on your home PCs, how many petabytes of hard drive space are you using?"). 1. There is no "database of latents". It does not exist. A user cannot get the training latents. They don't exist in the checkpoints. Period. The checkpoints hold neural network weights and biases for denoising, not latent images.[1] 2. Since there are no latents to look up, obviously it does not look up latents. Instead, it starts out with random latent noise (static), cross-products it with a textual latent generated from the text that the user types in, and then in a manner akin to seeing images in clouds (reverse image recognition[16]), "pushes and pulls" on the meaningful-text-with-meaningless-image latent (diffusion along a gradient), one step at a time, to make it coherent.[27]
2b. The weights and biases that lead to the statistical "understanding" of what makes said latent make more sense come from training having captured the statistical relationships of how things tend to be shaped across billions of images[3] - not just some random handful of specific images. 3. After a given number of steps, the now coherent text-with-image latent is converted into image space. At this point, the author is simply wasting the reader's time. Again, I cannot stress this enough: There. Is. No. Database. Of. Latent. Images. To. Collage. In any way, shape or form. Generation of an image makes a textual latent from what the user types in, and combines it with an image latent made of random noise. No other latents come into play. |
Conditioning with text promptsIn 2022, the diffusion technique was further improved by researchers in Munich. These researchers figured out how to shape the denoising process with extra information. This process is called conditioning. (One of these researchers, Robin Rombach, is now employed by Stability AI as a developer of Stable Diffusion.)
Only the dog in the lower left seems to be eating ice cream. The two on the right seem to be eating meat, not ice cream. The most common tool for conditioning is short text descriptions, also known as text prompts, that describe elements of the image, e.g.—“a dog wearing a baseball cap while eating ice cream”. (Result shown at right.) This gave rise to the dominant interface of Stable Diffusion and other AI image generators: converting a text prompt into an image. |
For once, we have two paragraphs without gross misrepresentation. To be more specific, and summing up what has been described thusfar:[28] 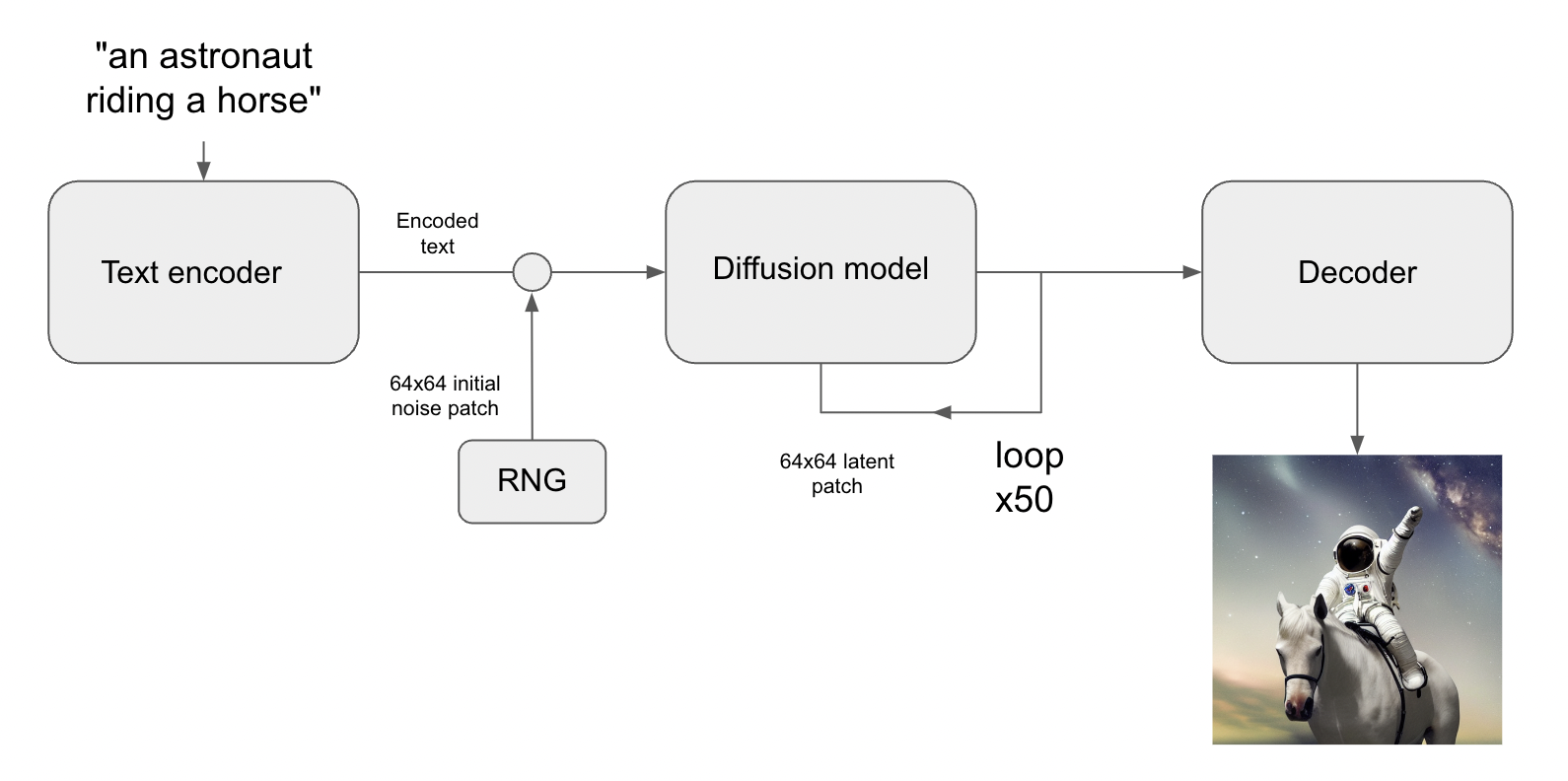
To repeat: your text turns into a textual latent; it gets cross-producted (combined) with an image latent that's just random noise; the diffusion model repeatedly "pushes and pulls" on it (gradient descent) to make the two be more coherent together; and then the latent is converted into an image. Notably absent: any "database of latents",[1] any "collaging", or anything other than what's basically inverse image-recognition.[16] TL/DR: "Hey, that cloud kind of looks vaguely like an astronaut and a horse - let's make it look more like an astronaut and a horse. I know how those things should be shaped because I've seen millions of them." |
|
The text-prompt interface serves another purpose, however. It creates a layer of magical misdirection that makes it harder for users to coax out obvious copies of training images. |
This claim is completely belied by the fact that you can enter no text whatsoever, or supply a random textual latent, and you still don't get "obvious copies of the training images". |
|
(though not impossible). Nevertheless, because all the visual information in the system is derived from the copyrighted training images, the images emitted—regardless of outward appearance—are necessarily works derived from those training images. |
The linked paper does raise actual issues, but not in the way that the author seems to think. To sum up: * The paper found that 1.88% of images generated with the original release of Stable Diffusion (v1.4) resembled at least one image in the training dataset with a similarity of greater than 0.5 (where 1 = exactly the same, 0 = doesn't at all resemble any image. * The paper explicitly states that this is not an inherent part of such algorithms: "previous studies of GANs have not found it, and our study of ImageNet LD did not find any evidence of significant data replication." * On the cause of this in the v1.4 release of Stable Diffusion, the authors speculate that the cause is its text conditioning, "a highly skewed distribution of image repetitions in the training set", and "the number of gradient updates during training is large enough to overfit on a subset of the data" To this, a number of key points must be raised: * Nobody wants a subset of the data to be overfit.[5][6][7][8][9] Nobody wants to create things similar to existing images, and if a subset were overtrained, it's a given that Stability AI would eliminate any overtraining that it was aware of. And furthermore, any amount of weighting that goes toward overfitting a small subset of the training dataset means that the rest is underfit, and little learned from it; they in effect "steal" part of that byte or so per image from the rest of the images. * V1.4 is now four releases old (with v1.5, v2.0, and v2.1 since then[29]); basically nobody uses it anymore for generation. * Using this to attack StabilityAI is one thing, but given that the authors specifically note it as being a property of Stable Diffusion v1.4 and that it is not generally applicable, using this argument to attack Midjourney is facetious. * Not to put too fine a point on it, but "images looking similar to other images" is something that happens on its own in any large dataset. To give examples from the paper, the images in yellow on the left were generated from the ImageNet model, while the images on the right were in its training dataset: 
It should be obvious that the non-generated images also look highly similar to each other; this is just the nature of random chance when it comes to large numbers of images. What the authors found, in the case of SD v1.4, that it happened to a greater degree than it should have, for the above stated reasons. |
The defendantsStability AIStability AI, founded by Emad Mostaque, is based in London. Stability AI funded LAION, a German organization that is creating ever-larger image datasets—without consent, credit, or compensation to the original artists—for use by AI companies. Stability AI is the developer of Stable Diffusion. Stability AI trained Stable Diffusion using the LAION dataset. Stability AI also released DreamStudio, a paid app that packages Stable Diffusion in a web interface. |
The very nature of a work meeting the standards of fair use means that you don't need "consent, credit, or compensation". And again, if one byte or so per image, creating works that do not resemble (much less infringe on) copyrighted works, to massively empower millions of people in artistic creation (plus the numerous other uses for LAION-400M, which is commonly used in research), is not fair use, then the concept of fair use has no meaning. Stability AI appears more than happy to let artists opt out (indeed, as mentioned before, it has a basically meaningless impact on the net quality, as any artist by and large just exists as an interpolation between existing points in the latent space[19]). But it has no legal obligation to do so, any more than it would have an obligation to let them opt out of parody, education, criticism, etc. |
DeviantArtDeviantArt was founded in 2000 and has long been one of the largest artist communities on the web. As shown by Simon Willison and Andy Baio, thousands—and probably closer to millions—of images in LAION were copied from DeviantArt and used to train Stable Diffusion. Rather than stand up for its community of artists by protecting them against AI training, DeviantArt instead chose to release DreamUp, a paid app built around Stable Diffusion. In turn, a flood of AI-generated art has inundated DeviantArt, crowding out human artists. When confronted about the ethics and legality of these maneuvers during a live Q&A session in November 2022, members of the DeviantArt management team, including CEO Moti Levy, could not explain why they betrayed their artist community by embracing Stable Diffusion, while intentionally violating their own terms of service and privacy policy. |
Being upset about being "crowded out" on a particular website by people enjoying their newfound ability to realize their artistic dreams with greater ease than before is not exactly grounds for a lawsuit. Many painters raged about the public fawning over the new technology of the camera (including none other than the founder of modern art criticism, Charles Baudelaire), saw photographers as failed artists, and despised them.[11] But "hating change" is not an infringement. |
MidjourneyMidjourney was founded in 2021 by David Holz in San Francisco. Midjourney offers a text-to-image generator through Discord and a web app. Though holding itself out as a “research lab”, Midjourney has cultivated a large audience of paying customers who use Midjourney’s image generator professionally. Holz has said he wants Midjourney to be “focused toward making everything beautiful and artistic looking.” To that end, Holz has admitted that Midjourney is trained on “a big scrape of the internet”. Though when asked about the ethics of massive copying of training images, he said— There are no laws specifically about that. And when Holz was further asked about allowing artists to opt out of training, he said— We’re looking at that. The challenge now is finding out what the rules are. We look forward to helping Mr. Holz find out about the many state and federal laws that protect artists and their work. |
Once again: what works? Copyright law is built around works,[18] and you have yet to show that even your clients, let alone anyone else, has works violated by infringing works that were not sufficiently transformatively different. Perhaps instead of focusing on heavy-handed threats, you start with actually addressing, you know, the most basic requirements of copyright law, that you actually have specific works being infringed on by specific other works? Once again the author uses heavy-handed cherry-picking on the quotations, leaving out Mr. Holz's pointed - and accurate - commentary on the technical difficulty of implementing what the anti-AI artists are demanding:
Rather than wasting resources on harassment suits, if anti-AI artists actually cared about this, they would be advised to instead put those resources to developing a registry and a means of identifying which works in a dataset may be copies of theirs, so that AI art developers, who would be more than happy (though are in no way required) to let artists opt out, can make use of it. Aka, doing something productive in regards to their supposed desire of having a "conversation about how AI will coexist with human culture and creativity." |
The plaintiffsOur plaintiffs are wonderful, accomplished artists who have stepped forward to represent a class of thousands—possibly millions—of fellow artists affected by generative AI. Sarah Andersen
Sarah Andersen is a cartoonist and illustrator. She graduated from the Maryland Institute College of Art in 2014. She currently lives in Portland, Oregon. Her semi-autobiographical comic strip, Sarah’s Scribbles , finds the humor in living as an introvert. Her graphic novel FANGS was nominated for an Eisner Award. Kelly McKernan
Kelly McKernan is an independent artist based in Nashville. They graduated from Kennesaw State University in 2009 and have been a full-time artist since 2012. Kelly creates original watercolor and acryla gouache paintings for galleries, private commissions, and their online store. In addition to maintaining a large social-media following, Kelly shares tutorials and teaches workshops, travels across the US for events and comic-cons, and also creates illustrations for books, comics, games, and more. Karla Ortiz
Karla Ortiz is a Puerto Rican, internationally recognized, award-winning artist. With her exceptional design sense, realistic renders, and character-driven narratives, Karla has contributed to many big-budget projects in the film, television and video-game industries. Karla is also a regular illustrator for major publishing and role-playing game companies. Karla’s figurative and mysterious art has been showcased in notable galleries such as Spoke Art and Hashimoto Contemporary in San Francisco; Nucleus Gallery, Thinkspace, and Maxwell Alexander Gallery in Los Angeles; and Galerie Arludik in Paris. She currently lives in San Francisco with her cat Bady. |
Three people for whom no effort has been made to show any kind of actual works infringing upon theirs. I would, contrarily, invite any readers to stop by the various AI art communities and actually speak with the artists incorporating AI tools into their workflows. They're real people, too, and deserve to be recognized.[15] I have genuine sympathy for the plaintiffs in this case. Not because "they're having their art stolen" - they're not - but because they're akin to a whittler who refuses to get power tools when they hit the market, insisting on going on whittling and mad at the new technology that's "taking our jobs!" When the one who is undercutting their job potential is themselves. Jevon's Paradox is real. Back when aluminum first came out, it was a precious metal - "silver from clay". Napoleon retired his gold and silver tableware and replaced it with aluminum. The Washington Monument was capped with a tiny block of what was then the largest piece of aluminum in the world.[30] Yet, today - where aluminum is a commodity metal costing around $2/kg, rather than a small fortune - the total market is vastly larger than it was when it was a precious metal. Because it suddenly became affordable, sales surged, and that overcame the reduction in price. AI art tools increase efficiency, yes. Contrary to myth, they rarely produce professional-quality outputs in one step, but combined into a workflow with a human artist they yield professional results in much less time than manual work. But that does not inherently mean a corresponding decrease in the size of the market, because as prices to complete projects drop due to the decreased time required, more people will pay for projects that they otherwise could not have afforded. Custom graphics for a car or building. An indie video game. A mural for one's living room. All across the market, new sectors will be priced into the market that were previously priced out. What can be said, however, is those who refuse to acknowledge advancements in technology and instead fight against them are like whittlers mad at power tools. Yes, people will still want hand-made woodwork, and it'll command a premium. But you relegate yourself to a smaller market. |
Contacting usIf you’re a member of the press or the public with other questions about this case or related topics, contact stablediffusion_inquiries@saverilawfirm.com . (Though please don’t send confidential or privileged information.) This web page is informational. General principles of law are discussed. But neither Matthew Butterick nor anyone at the Joseph Saveri Law Firm is your lawyer, and nothing here is offered as legal advice. References to copyright pertain to US law. This page will be updated as new information becomes available.
|
This response was created by tech enthusiasts uninvolved in the case, and not lawyers, for the purpose of fighting misinformation. |
|
|







![[2]](img/steps.png){kind=link}